파이썬의 Selenium을 이용해 구글에서 이미지 다운로드를 자동화하기
이 프로그램을 만들게 된 계기
회사에서 브랜드 3000개에 대한 로고 이미지를 다운로드할 일이 있었습니다. 이 일을 전부 제 손으로 하기에는 너무나 무리라는 생각이 들었고, 구글에 검색해서 이미지를 다운로드할 수 있도록 자동화된 프로그램을(구글링을 통해) Selenium으로 만들었습니다.
참고에는 다음 사이트를 활용하였습니다.
자세한 내용은 여기를 참조
작동 방식
이 프로그램은 아래와 같은 순서로 작동합니다.
1)검색하고자 하는 키워드의 리스트를 입력 받습니다.
2)입력받은 키워드를 구글에 이미지로 검색합니다.
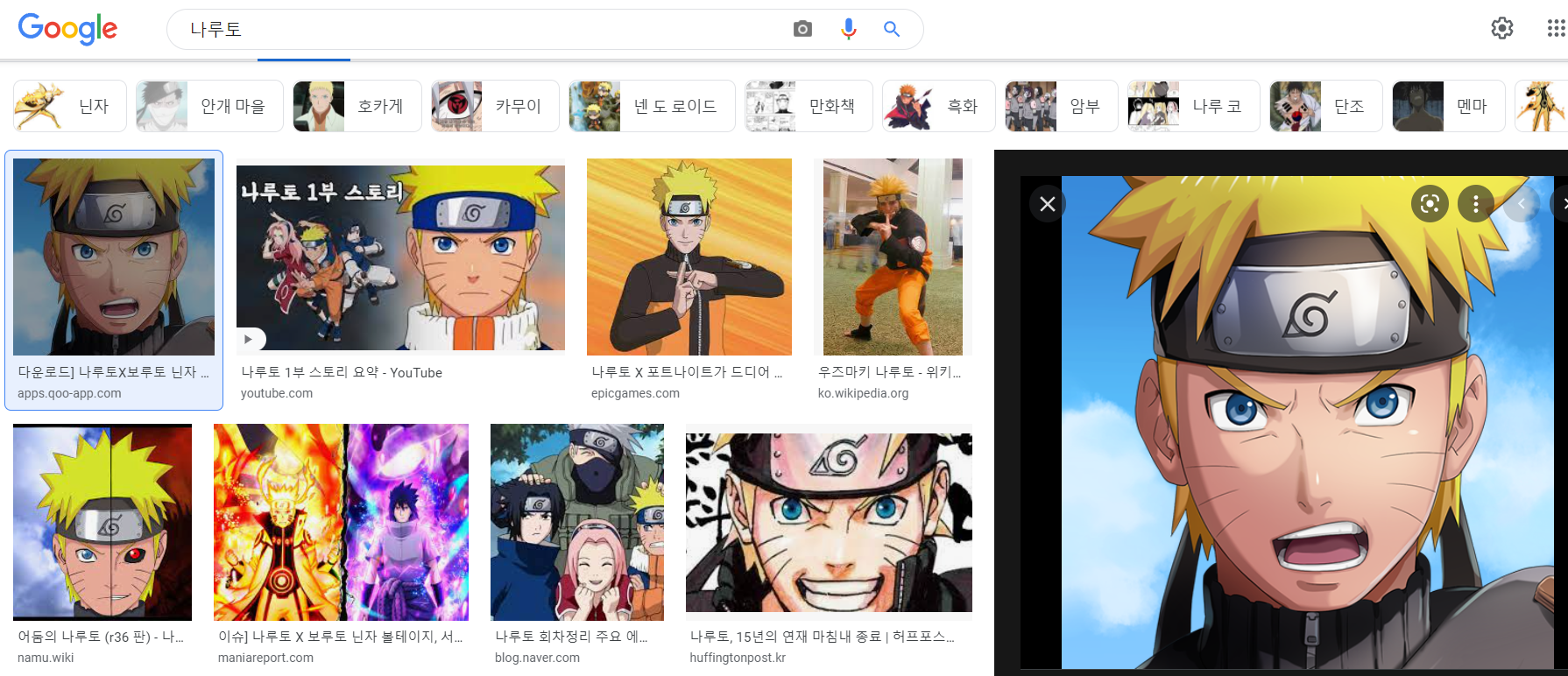
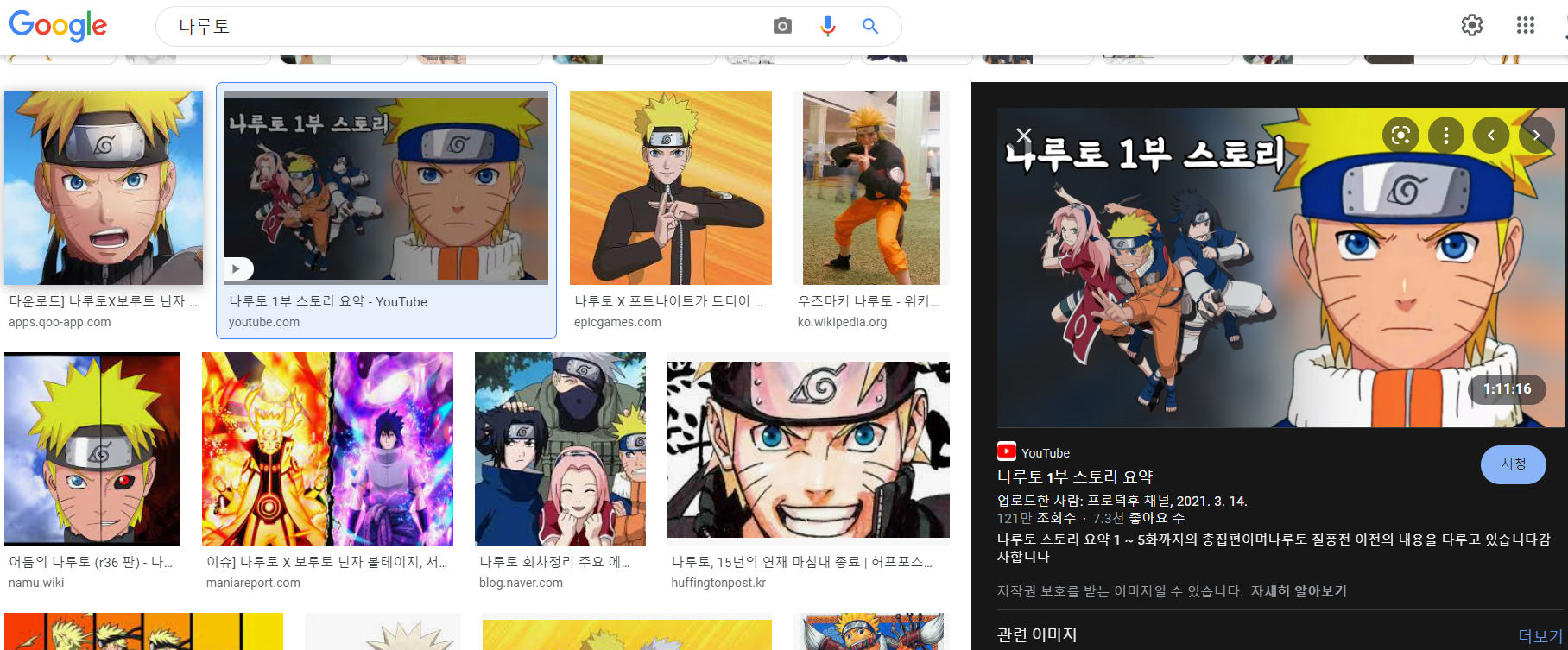
3)가장 상단(맨 위 가장 왼쪽)에 노출된 이미지를 클릭하고, 클릭시 PC 기준으로 오른쪽에 뜨는 이미지 중 ‘가장 큰 이미지’를 다운로드 받습니다.
4)그 다음은 상단에서 그 다음으로 노출된 이미지(맨 위 왼쪽 두번째 이미지)를 클릭하고, 마찬가지로 ‘가장 큰 이미지’를 다운로드합니다. 키워드 검색시 노출되는 순서에 따라서, 이를 반복하는데요. 이미지를 원하는 숫자만큼 다운로드 받을 수 있습니다.
5)다운로드 받은 이미지를, 키워드 이름으로 만든 폴더에 저장합니다.
예를 들면 ‘나루토’를 이미지로 검색하고, 검색 결과에서 가장 왼쪽의 이미지를 클릭하면 오른쪽에 검은 배경으로 큰 이미지가 뜹니다. 이 큰 이미지를 다운로드 합니다. 그 다음 검색 결과에서 왼쪽의 이미지를 클릭하고 반복합니다.
소스코드
소스 코드는 아래와 같습니다. 셀레니움을 설치하고 chromedriver를 다운로드 받는 법에 대해서는 생략하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from urllib import request
import os
import time
import pandas as pd
#폴더를 만들기 위한 메서드
def createFolder(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print ('Error: Creating directory. ' + directory)
#이미지 다운로드를 위한 메서드
def image_downloader(name_list): #name_list: 검색하고자 하는 키워드 목록을 담은 리스트
for i in name_list:
name = str(i)
directory = #위에서 선언한 name 변수를 활용해서, 파일을 만들 directory를 선언
createFolder(directory)
#검색 결과가 나오지 않을 수 있기 때문에, try-error를 활용함
#검색
try:
elem = driver.find_element_by_name('q') # class='gLFyf gsfi'
elem.clear()
elem.send_keys(name)
elem.send_keys(Keys.RETURN)
time.sleep(1)
#검색 결과로 얻은 이미지의 수가 10개가 넘으면 10개만, 10개 미만이면 가능한만큼 다운로드를 시도함
if len(driver.find_elements_by_css_selector('img.rg_i.Q4LuWd')) > 10:
num = 10
else:
num = len(driver.find_elements_by_css_selector('img.rg_i.Q4LuWd'))
except:
continue
for j in range(num):
#마찬가지로 과정 중 오류가 있을 수 있기 때문에, try-error로 구현
try:
driver.find_elements_by_css_selector('img.rg_i.Q4LuWd')[j].click() #검색 결과로 나온 이미지를 순서대로 클릭
time.sleep(1)
big_image = driver.find_element_by_css_selector('img.n3VNCb') #가장 큰 이미지를 선택
bigImage_url = big_image.get_attribute('src')
request.urlretrieve(bigImage_url, '%s/%s'%(name, name) + str(j+1) + ".jpg") #이미지를 다운로드해서 폴더에 저장
except:
pass
driver.close()
#image_downloader 메서드 실행
name_list = [] #name_list 지정
# driver 실행
driver = webdriver.Chrome(path) #path에 자신의 chromedriver가 있는 위치를 지정
driver.get('https://www.google.co.kr/imghp?hl=ko&ogbl')
time.sleep(0.5) #페이지 로딩에 걸리는 시간
image_downloader(name_list)
결과
‘나루토’를 겸색하여 10개의 이미지를 다운로드 받은 결과는 다음과 같습니다.
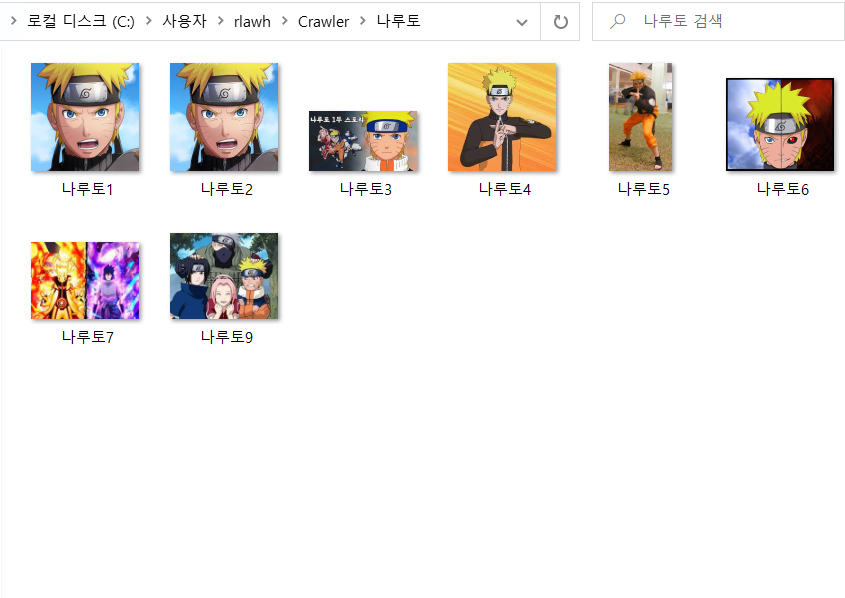
자세히 보시면 1~10까지 이미지 10개가 생성되어야하는데, 8번과 10번이 빠진채로 다운로드되었음을 확인하실 수 있습니다. 이는 Try-error 처리로 인해서 다운로드 받지 못한 이미지가 있기 때문입니다.
실제 검색결과 이미지와 비교하시면, 검색 결과 내에서 그럭저럭 잘 다운로드된 것을 확인하실 수 있습니다. 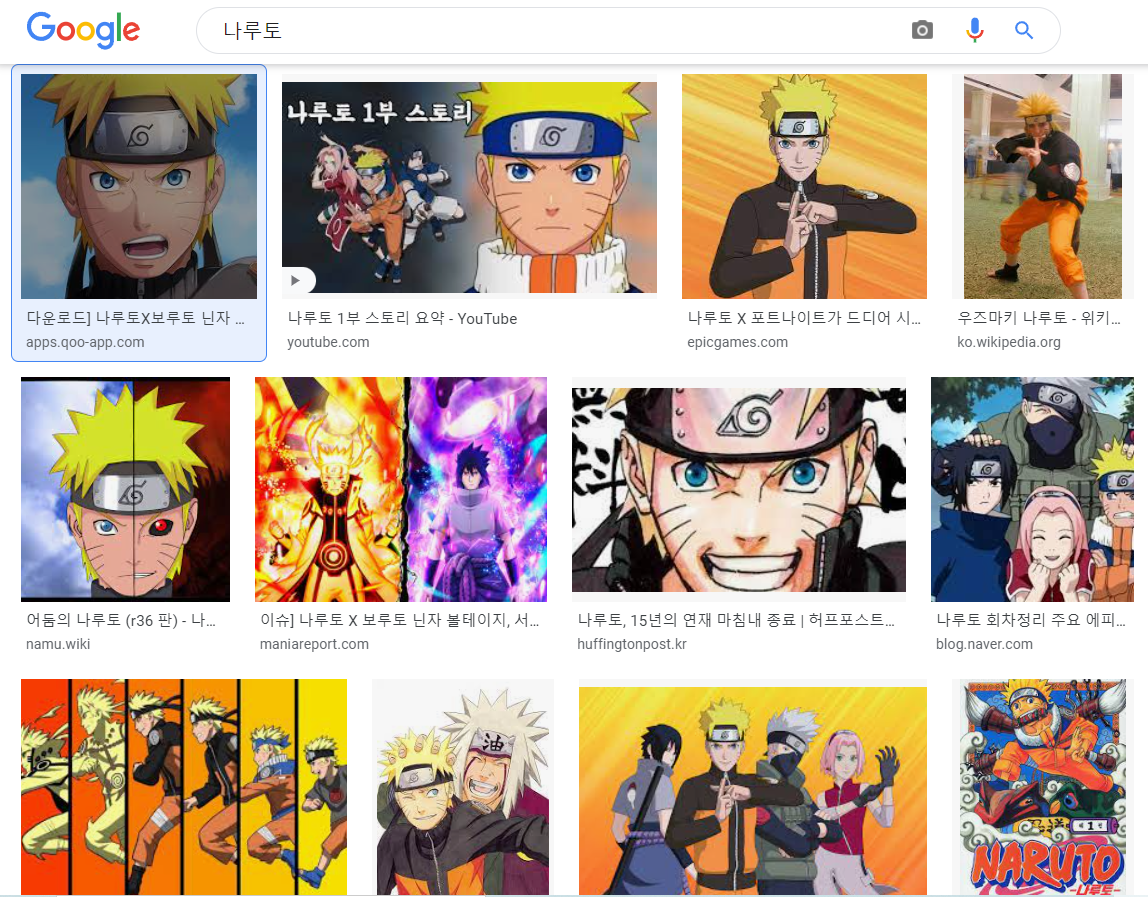
앞서 언급드렸듯이, 저같은 경우는 브랜드 3000개의 로고를 검색해야했기에, 검색 조건에 브랜드 이름 + 로고를 넣어서 검색을 했는데요. 3000개를 10개씩 다운로드 받다보니까 시간이 정말 오래걸리기도 했고, 그냥 검색 결과 이미지를 가져오는 것이다보니, 로고가 아닌 경우가 있더라구요. 그러면…로고인지 아닌지 여부를 판별해주는 분류기가 있으면 좋지 않을까? 라는 생각이 들었습니다. 이 분류기에 대해서는 다음에 글을 적고자 합니다.
Comments powered by Disqus.